Abstract
Modeling daytime changes in high resolution photographs, e.g., re-rendering the same scene under different illuminations typical for day, night, or dawn, is a challenging image manipulation task. We present the high-resolution daytime translation (HiDT) model for this task. HiDT combines a generative image-to-image model and a new upsampling scheme that allows to apply image translation at high resolution. The model demonstrates competitive results in terms of both commonly used GAN metrics and human evaluation. Importantly, this good performance comes as a result of training on a dataset of still landscape images with no daytime labels available.

HiDT Explained
Model Overview
Translation Network
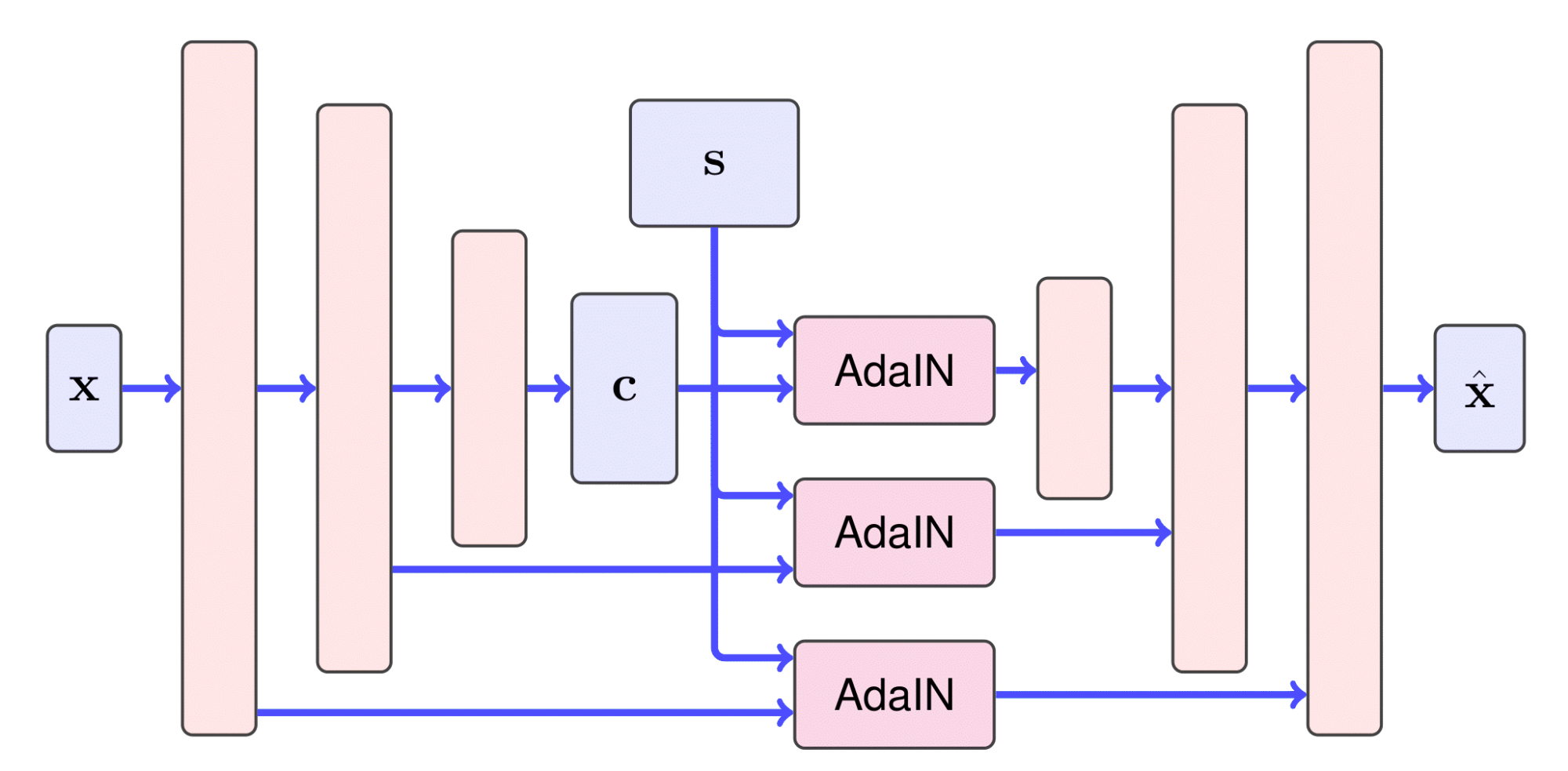
The HiDT model aims to extract independent encodings of content $c$ and style $s$ from an input image $x$ by using its own architectural bias, with no explicit supervision from the training set, and then to construct images with new content-style combinations. To create a plausible daytime landscape image, the model should preserve details from the original image. To satisfy this requirement, we enhance the FUNIT-inspired encoder-decoder architecture with dense skip connections between the downsampling part of the content encoder and the upsampling part of the decoder. Unfortunately, regular skip connections would also preserve the style of the initial input. Therefore, we introduce an additional convolutional block with AdaIN and apply it to the skip connections.
Enhancement Pipeline
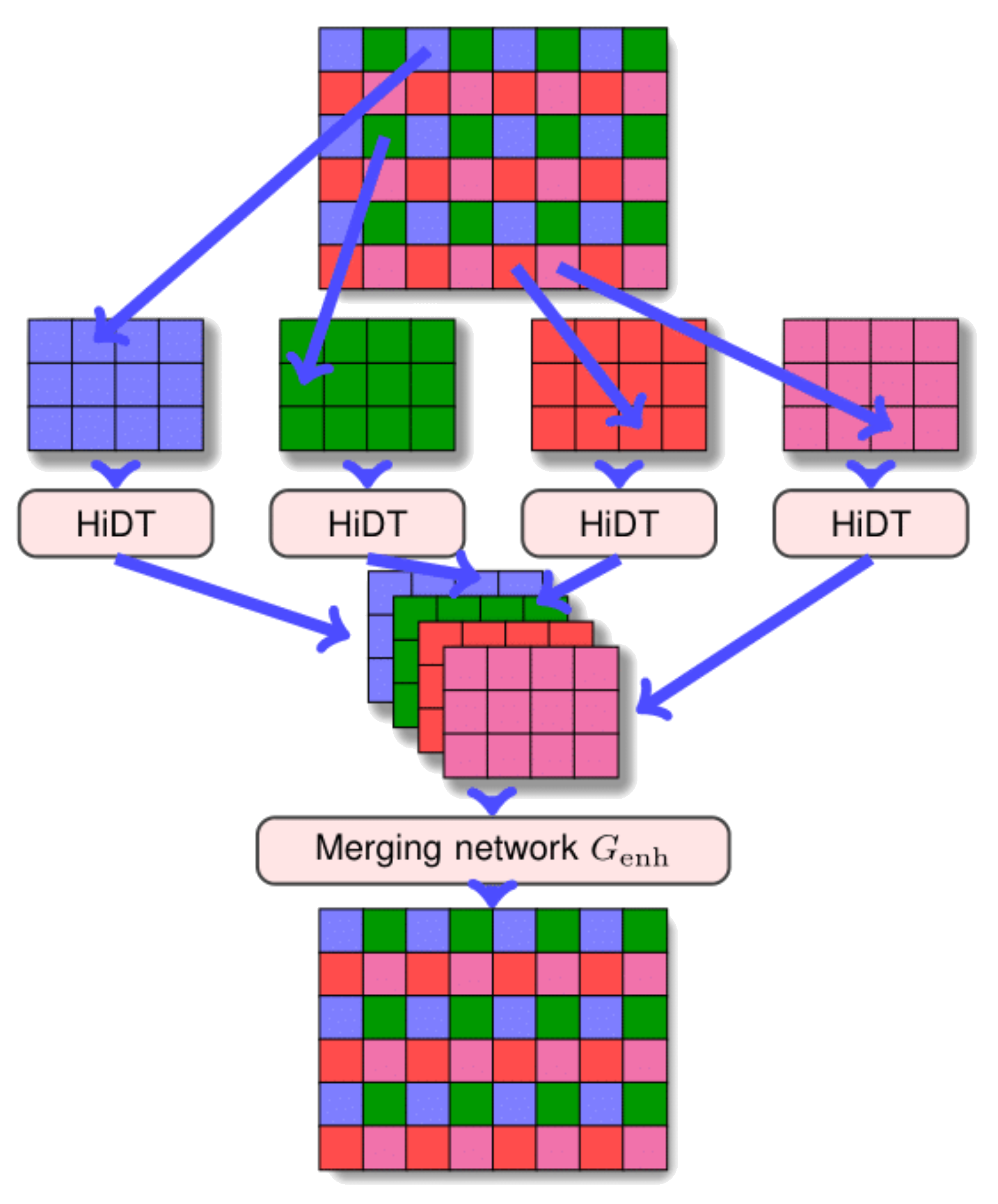
Training a network which can effectively operate with high resolution images is difficult due to the hardware constraints in both memory and computation time. Inspired by existing multiframe image restoration methods, we propose to use a separate enhancement pipeline to upscale the translated image and simultaneously remove the artifacts that are typical for the trained and frozen translation net. Therefore, the input is split into subimages (color-coded in the scheme below), that are processed individually by HiDT at medium resolution and then merged together with $G_{enh}$ network.
Results
Landscapes

Swapping styles between two images. Original images are shown on the main diagonal, and off-diagonal images correspond to swaps. Swapping successfully combines both content and style from two input images into naturally-looking photographs.

The original content image (top left), transferred to randomly sampled styles from prior distribution. The results demonstrate the diversity of possible outputs.
Linear interpolation between two extracted styles (lighting conditions) on our main dataset. The leftmost column contains original images while the topmost row contains the two images the endpoint styles were extracted from. Linear interpolation delivers smooth transition between styles, e.g. cloudy and clear sky.

Interpolation between the styles of dusk and sunset.
Artworks

Linear interpolation between two extracted styles (lighting conditions) by the HiDT model, trained on our dataset of landscape photos. The leftmost column contains artworks in realism style.


Perhaps surprisingly, HiDT model, trained on a dataset of paintings, is capable of artistic style transfer as well. Original images are shown on the main diagonal.
Citation
I. Anokhin, P. Solovev, D. Korzhenkov, A. Kharlamov, T. Khakhulin, A. Silvestrov, S. Nikolenko, V. Lempitsky, and G. Sterkin. "High-Resolution Daytime Translation Without Domain Labels." In 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).